
Java: Jednoduchý česko-anglický slovník
Naprogramovat jednoduchý anglicko-český a česko-anglický slovník je velmi jednoduché, co potřebujete je pouze databáze slovíček a frází, ve kterých budete vyhledávat.
Základ jakéhokoli slovníku jsou přeložená slovíčka a fráze, ve kterých může program vyhledávat.
Pro můj jednoduchý slovník jsem se rozhodl využít GNU/FDL anglicko-český slovník, který obsahuje několik tisíc přeložených slov.
Jednotlivá slova jsou uložena ve slovníku vždy na jednom řádku a to pustupně takto:
- anglické slovo [TAB]
- české slovo [TAB]
- poznámky [TAB]
- speciální poznámky [TAB]
- jméno překladatele
Některé řádky ve slovníku obsahují pouze poznámky. Tyto řádky jsou započaty znakem #, a tyto řádky jsou pro data ve slovníku nepodstatná a proto se jim při načítání slov vyvarujeme.
Pro náš jednoduchý slovník, nás budou zajímat pouze tři první sloupce. Tedy budeme potřebovat český a anglický význam slova a po případě ještě poznámku ke slovu, která značí o jaký slovní druh slova se jedná, nebo upřesňují daný význam slova.
Po shlédnutí formátu uložených dat se můžeme pustit do práce.
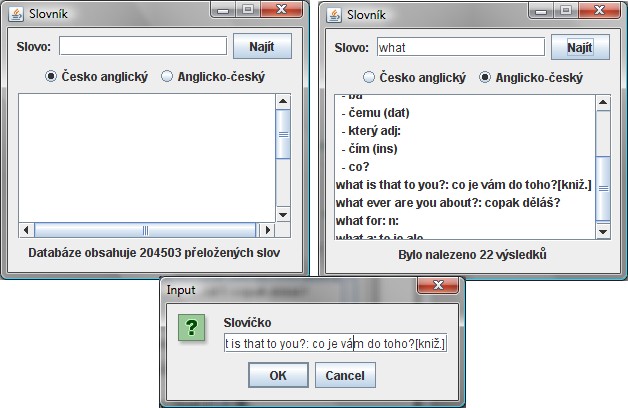
Slovník
Slovník bude obsahovat jednoduché grafické rozhraní, ve kterém bude možnost zadat hledané slovo, spustit vyhledávání kliknutím na tlačítko hledat a sledovat výsledky vyhledávání.
Navíc zde bude možnost přepínat mezi anglicko-českým nebo česko-anglickým slovníkem.
Program doplníme o stavový řádek, ve kterém se uživateli budou vypisovat informace o průběhu hledání, nebo informace o databázi slovníku.
Načtení dat
Základem celého slovníku jsou data.
Program bude fungovat tak, že si při spuštění načte všechna data do paměti a v nich bude později vyhledávat.
Pro uložení jsem zvolil tři ArrayListy, do kterých si zvlášť uložím česká slovíčka, anglická slovíčka a poznámky. Všechny tři Listy budou mít stejné indexy pro stejné řádky v souboru, takže nebude problém dle těchto indexů rozlišovat jednotlivá slova.
Funkce funguje velmi jednoduše:
Po spuštění zjistí, zda existuje soubor se slovíčky, v mém případě se jedná o soubor directory/slovnik_data_utf8.txt.
Pokud takový soubor existuje, začne jej po řádcích číst a pomocí funkce split rozdělovat dle tabulátorů.
Vždy po načtení nového řádku nejprve kontroluje, zda není první znak #, a tím pádem se nejedná o poznámku v souboru.
Nakonec do stavového řádku napíše výsledek načítání:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
/** * @function load_data * @return */ public void load_data() { //pokud existuje soubor direcotory/slovnik_data_utf8.txt, nacteme z nej vsechna data File file = new File("directory/slovnik_data_utf8.txt"); if (!file.exists()) { //pokud soubor neexistuje vypiseme to ve stavovem radku. statusbar.setText("File doesn't exists"); return; } try { //vytvoreni bufferdReaderu BufferedReader in = new BufferedReader(new InputStreamReader( new FileInputStream("directory/slovnik_data_utf8.txt"), "UTF8")); String line = null; try { line = in.readLine(); } catch (IOException e) { e.printStackTrace(); } //cteme soubor postupne po radcich |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
//cteme soubor postupne po radcich while (line != null) { //pokud soubor zacina #, jedna se o poznamku, kterou nebereme v uvahu if( !line.trim().startsWith("#") ){ //rozdelime radek dle tabulatoru. String [] lines = line.split("t"); //pokud je velikost vetsi nez 1, existuji anglicka i ceska slova if( lines.length > 1 ){ czech.add(lines[1].trim()); english.add(lines[0].trim()); //pokud je velikost vetsi nez 2, existuje i dalsi vyznam slova if( lines.length > 2 ) meaning.add(lines[2].trim()); else meaning.add(null); } } try { line = in.readLine(); } catch (IOException e) { e.printStackTrace(); } } |
|
1 2 3 4 5 6 7 8 9 10 11 |
} catch (UnsupportedEncodingException e) { e.printStackTrace(); } catch (FileNotFoundException e) { e.printStackTrace(); } //do stavoveho radku vypiseme informace o poctu nactenych slov, ktere slovnik obsahuje this.statusbar.setText("Databáze obsahuje " + czech.size() + " přeložených slov"); //hodnotu promenne inicializace nastavime na 1 this.inicializace_is_completed = 1; return; } |
Hledání slov
Pokud máme načtena všechna data, můžeme v nich začít vyhledávat.
Funkce pro načtení dat bude obsahovat tři vstupní parametry. První z nich bude hledané slovo a další dva budou seznamy slovíček.
Seznamy slovíček budeme do funkce předávat takovým způsobem, že na prvním místě bude seznam slovíček ve kterých vyhledáváme, a tím pádem budeme moci funkci používat jak pro anglicko-české vyhledávání tak pro opačné. Na druhém místě (tedy třetí parametr) bude seznam, ze kterého vypisujeme nalezená slova.
Pro vyhledávání jsem zvolil dvě TreeMapy. Do první z nich se ukládají nalezená slovíčka a do druhé nalezené fráze.
Při vyhledávání projdeme v cyklu celý seznam, který je do funkce předaný jako druhý parametr a v něm vyhledáváme slovíčka.
Po nalezení známe index, pod kterým je v seznamu, předaném jako třetí parametr jeho přeložený význam.
Při vyhledávání hledáme jak slovíčka, tak fráze, které na dané slovo začínají.
U výpisu nejprve vypíšeme do JListu nalezená slovíčka a až pod nimi fráze, pro lepší orientaci.
Nakonec vypíšeme informace do stavového řádku programu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
/** * @function search_words * @param word * @param search_list * @param output_list */ public void search_words(String word, List search_list, List output_list ){ int word_hash = word.hashCode(); //vymazeme stavajici seznam nalezenych slov listModel.removeAllElements(); //vytvorime dve hashMapy Map tm = new HashMap(); Map tm2 = new HashMap(); for( int i = 0; i < search_list.size(); i++ ){ //hledame slova if( String.valueOf( search_list.get(i)).toLowerCase().hashCode() == word_hash ){ tm.put(String.valueOf(output_list.get(i)), meaning.get(i) ); } //dale hledame fraze, ktere danym slovem zacinaji if( String.valueOf( search_list.get(i)).toLowerCase().startsWith( word + " ") && word.length() > 1 ){ tm2.put( String.valueOf( search_list.get(i)) + ": " + String.valueOf(output_list.get(i)), meaning.get(i) ); } } List myList = new ArrayList(tm.keySet() ); List meaning_values = new ArrayList( tm.values() ); for( int i = 0; i < myList.size(); i++ ){ String s = " - " + myList.get(i); if( meaning_values.get(i) != null ){ s = s + " " + meaning_values.get(i); } listModel.addElement(s); } //z obou HashMap vytvorime ArrayListy List myList2 = new ArrayList(tm2.keySet() ); List meaning_values2 = new ArrayList( tm2.values() ); //do JListu vypisujeme nejprve samotna slovicka a potom fraze for( int i = 0; i < myList2.size(); i++ ){ String s = String.valueOf( myList2.get(i) ); if( meaning_values2.get(i) != null ){ s = s + String.valueOf( meaning_values2.get(i) ); } listModel.addElement(s); } //informace o hledani vypiseme do stavoveho radku if( myList.size() == 0 ) statusbar.setText("Nebylo nalezeno žádné slovíčko."); else statusbar.setText("Bylo nalezeno " + ( myList.size() + myList2.size() ) + " výsledků"); } |
V grafickém rozhraní bude možnost přepínat si mezi zvoleným jazykem pro hledání. Dle přepnutí této hodnoty se nám bude upravovat hodnota v proměnné „rezim“, podle této proměnné můžeme předávat správné parametry do funkce search_words:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
/** * @function find_and_print_words */ public void find_and_print_words(){ //zjistime hledane slovo String search_string = searchbox.getText().trim(); //pokud existuje slvo, budeme hledat if( search_string.length() == 0 ) return; //dle rezimu predame funkci pro hledani sprvane poradi parametru if( rezim == 0 ){ search_words(search_string, czech, english); } else{ search_words(search_string, english, czech); } } |
Grafické rozhraní
Kód grafického rozhraní si můžete prohlédnout na konci článku, kde je umístěn kompletní zdrojový kód programu.
Základem grafického rozhraní je pole pro vyhledávání a seznam pro výpis nalezených slov ve formě Jlistu.
Po odeslání hledaného slova se nejprve zkontroluje, zda řetězec není prázdný a pokud ne, volá se funkce find_and_print_words.
Tato funkce rozhodne dle nastaveného režimu o posloupnosti parametrů a volá funkci search_words.
Kompletní zdrojový kód
Kvůli délce zdrojového kódu jsem jej umístil do externího souboru, který si můžete stáhnout.
Soubor neobsahuje funkci Main!
directory.java
Dobrý den, mám problémy s rozchozením Vašeho slovníku. Program sice běhá ale nenajde buď nic nebo vypíše jenom nesmysly. Sadu slovíček jsem si stáhl a tu to i načte, ale jak říkám problém je s vyhledáváním. Myslíte, že byste mi mohl poslat celý zdrojový kód i s funkcí main?
me taky prosim.
Metoda main muze vypadat takto:
public static void main(String args[]) {
new Directory();
}
V metode load_data() je chyba:
//rozdelime radek dle tabulatoru.
String [] lines = line.split("t");
je spatne a spravne je toto:
String [] lines = line.split(" ");
Reaguji na vlastni komentar (zda se, ze funkcnost reakce na komentare tu ma problemy…)
Behem postu doslo k uprave meho textu, takze jeste jednou. Na radku
String [] lines = line.split("t");
ma byt pred znakem "t" backslash.